




Natural Language Processing (NLP), which is a subfield of Artificial Intelligence that deals with human interactions with computers. NLP is being used in a number of products and services that we use every day by helping us to organize the massive chunks of text data and solve problems such as Machine Translation, Autocorrect, Question, and Answering (Q&A), Relationship Extraction, Sentiment Analysis, and Speech Recognition, etc.
What is NLP-Pipeline?
If we have an NLP problem, we would start approaching it by breaking the problem down into several sub-problems and then develop a step-by-step procedure to solve them. As language processing is also involved, we would list all the types of text processing needed at each step. This series of steps involved in building any NLP model is called the NLP pipeline. NLP pipeline consists of three major stages: Text Processing, Feature Extraction, Modelling. Each stage alters text in some way and produces a result for the next stage's needs.
Text Processing
This is the first stage of the NLP pipeline that discusses how we take raw input text, clean it, and alter it into a form suitable for feature extraction.
Cleaning —
In this step, we remove all irrelevant items that don’t add much value towards analyzing text, such as HTML tags, punctuation, extra spaces.
Stop Words Removal —
We remove the filler words (a, an, the, etc.) which add no significant meaning, also called stop words.
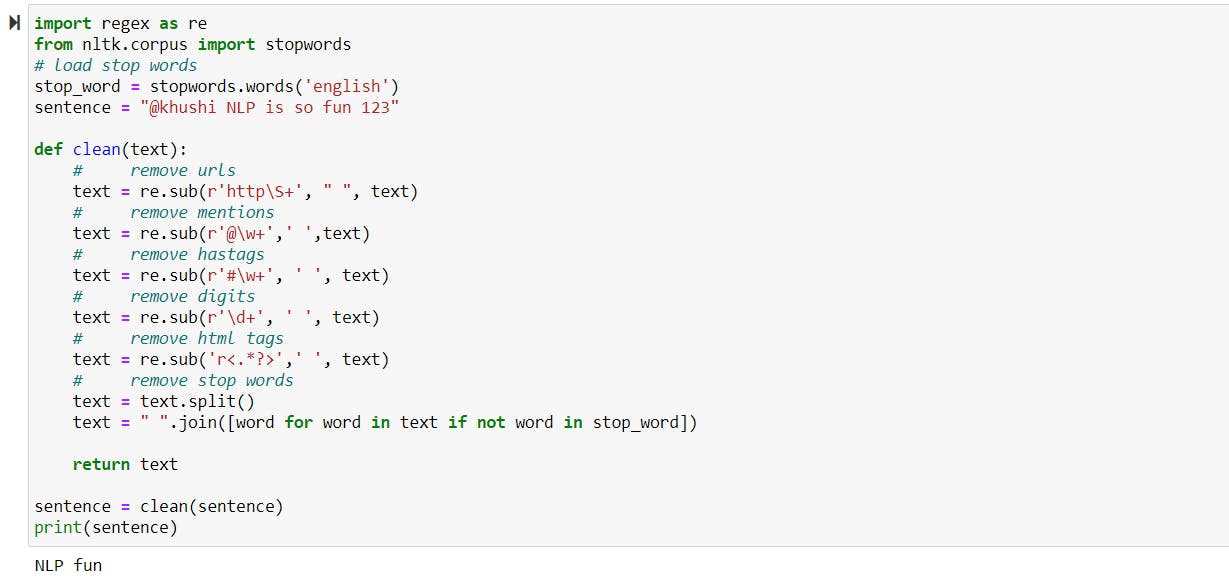
Tokenization —
The process of breaking a sentence, paragraph, or whole document into smaller units, such as individual words or terms known as tokens.

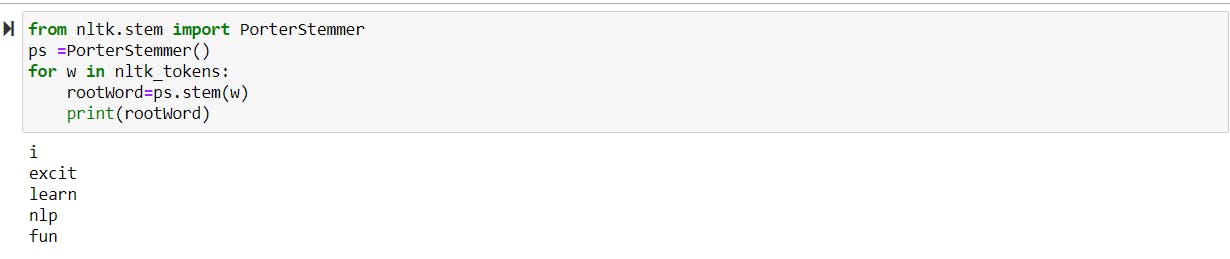
Stemming —
Word stems are the base form of a word, and we create new words by attaching affixes to them. For example, you can add affixes to the base wordplay and form new words like playing, player, and plays. Different types of stemmers in NLTK are PorterStemmer, SnowballStemmer, LancasterStemmer.
• Porter is the most commonly used stemmer and also the most computationally intensive of the algorithms.
• Snowball: has slightly faster computation time than porter, with a reasonably large community around it.
• Lancaster: is a very aggressive stemming algorithm, as many shorter words will become totally confusing. The fastest algorithm, but if you want more distinction, it is not the tool you would want.
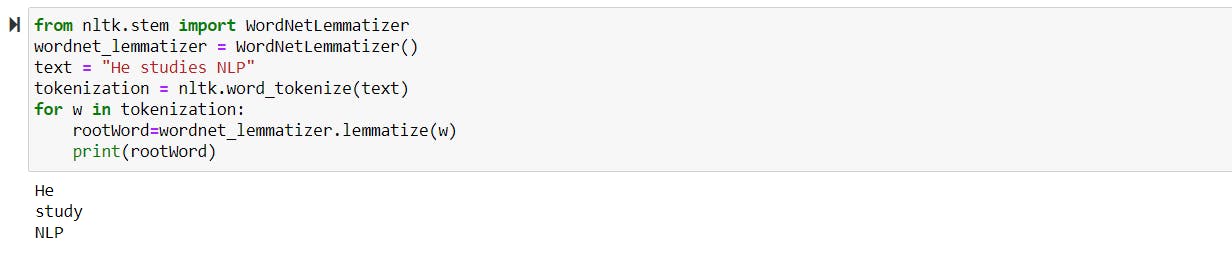
Lemmatization —
Lemmatization is the process of figuring out the root form or most basic form of each word in the sentence. It is very similar to stemming. The difference is that it takes into consideration the morphological analysis of the words. So, lemmatization can even convert words that stemmer can’t solve, for example converting “studies” to “study”.
Feature Extraction:
The second step is Feature Extraction that produces feature representations suitable for the appropriate type of NLP task and the type of model that is going to be used.
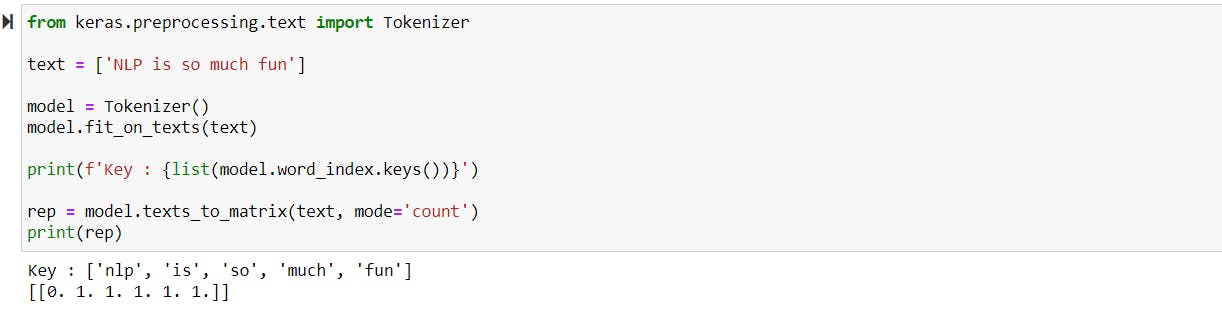
Bag of words (BOW) model
Bag of words is a representation of text describing the occurrence of words within a document. It consists of two things: A vocabulary of known words and a measure of the presence of known words. For example, while performing a sentiment analysis on tweets, each tweet is considered a document.
Limitations of Bag-of-Words
It treats every word like they are equally important when some words occur more frequently. For example, in a medical document, health and disease are very common terms.
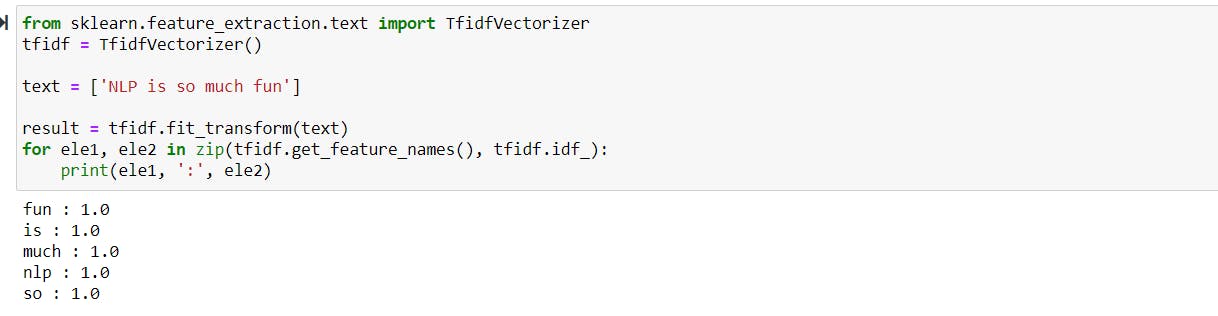
Term Frequency — Inverse Document Frequency (TF-IDF)
The limitation of Bag of words can be solved by counting a number of documents in which each word occurs, known as document frequency, and then dividing the term frequency by the document frequency of that term. It helps highlight the words that are more unique to a document. This approach is known as Term Frequency — Inverse Document Frequency (TF-IDF).
Modeling:
In the last step, design a model and fit its parameters to training data, use an optimization procedure, and then use it to make predictions about unseen data.